

前回は、機械学習を実際に行って、正解率が「0.825」のモデルを構築することができました。
しかしながら、別のアルゴリズムを使うと、より正解率の高いモデルを構築できるかもしれません。
そこで、今回は別のアルゴリズムを使って学習させ、正解率の高いモデルを構築したいと思います。
よろしくお願いします!
前回のおさらい
前回は、以下のようなコードを実行したと思います。
# 手書きの数字のデータを読み込む
from sklearn import datasets
digits = datasets.load_digits()
X = digits.images
y = digits.target
X = X.reshape((-1, 64))
# データをトレーニング用とテスト用に分ける
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
# データを学習
from sklearn.naive_bayes import GaussianNB
classifier = GaussianNB()
classifier.fit(X_train, y_train)
# 予測して精度を見る
from sklearn import metrics
from sklearn.metrics import accuracy_score
y_pred = classifier.predict(X_test)
print(accuracy_score(y_test, y_pred))すると、正解率は「0.825」という値が出ましたね
前回は、「ナイーブベイズ」というアルゴリズムを用いましたね
よく覚えていましたね。
今回は、「# データを学習」のブロックのところを書き換えて、別のアルゴリズムで学習させます。
別のアルゴリズムで学習させよう
では、下記のコードを見てみてください。
# 手書きの数字のデータを読み込む
from sklearn import datasets
digits = datasets.load_digits()
X = digits.images
y = digits.target
X = X.reshape((-1, 64))
# データをトレーニング用とテスト用に分ける
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
# データを学習
from sklearn.svm import SVC
classifier = SVC()
classifier.fit(X_train, y_train)
# 予測して精度を見る
from sklearn import metrics
from sklearn.metrics import accuracy_score
y_pred = classifier.predict(X_test)
print(accuracy_score(y_test, y_pred))「# データを学習」の部分が変わりましたね。
その通りです。
前回は、「ナイーブベイズ」というアルゴリズムを使って学習したのですが、今回は「サポートベクターマシン(SVM)」というアルゴリズムを用いて学習させます。
それでは、実行させてみましょう。
ファイル名は、「ml2」としてください。
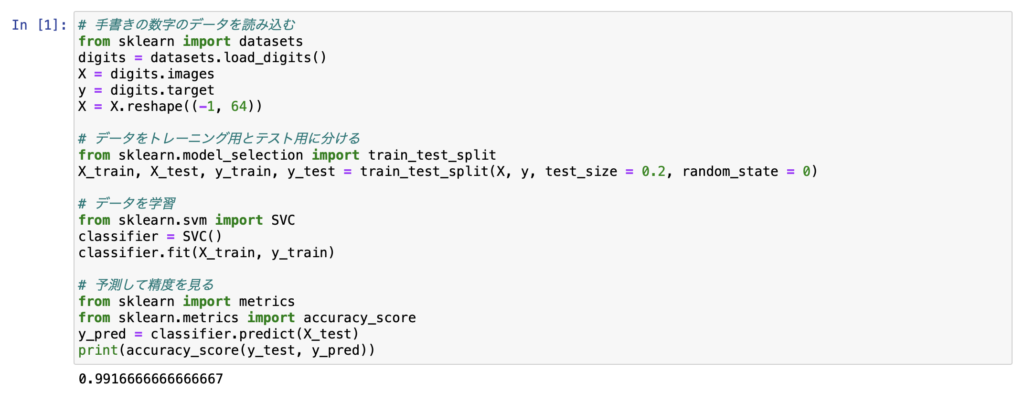
正解率が、「0.991666…」になりました。
めちゃくちゃ高いですね!
よくできました!
高い正解率を得ることができましたね。
この結果から、ナイーブベイズよりもSVMの方が良いモデルが構築できることが分かりました。
- 学習の際、使用するアルゴリズムを変えることで、より良いモデルが構築できる可能性がある
まとめ
今回は、アルゴリズムを変えて、より良いモデルを構築しました。
アルゴリズムを変えることで、正解率も変わることが分かりました。
次回は、最終回です!
いよいよ、あなたが書いた数字をAIに判別させます。
お楽しみに!

